
Übersicht
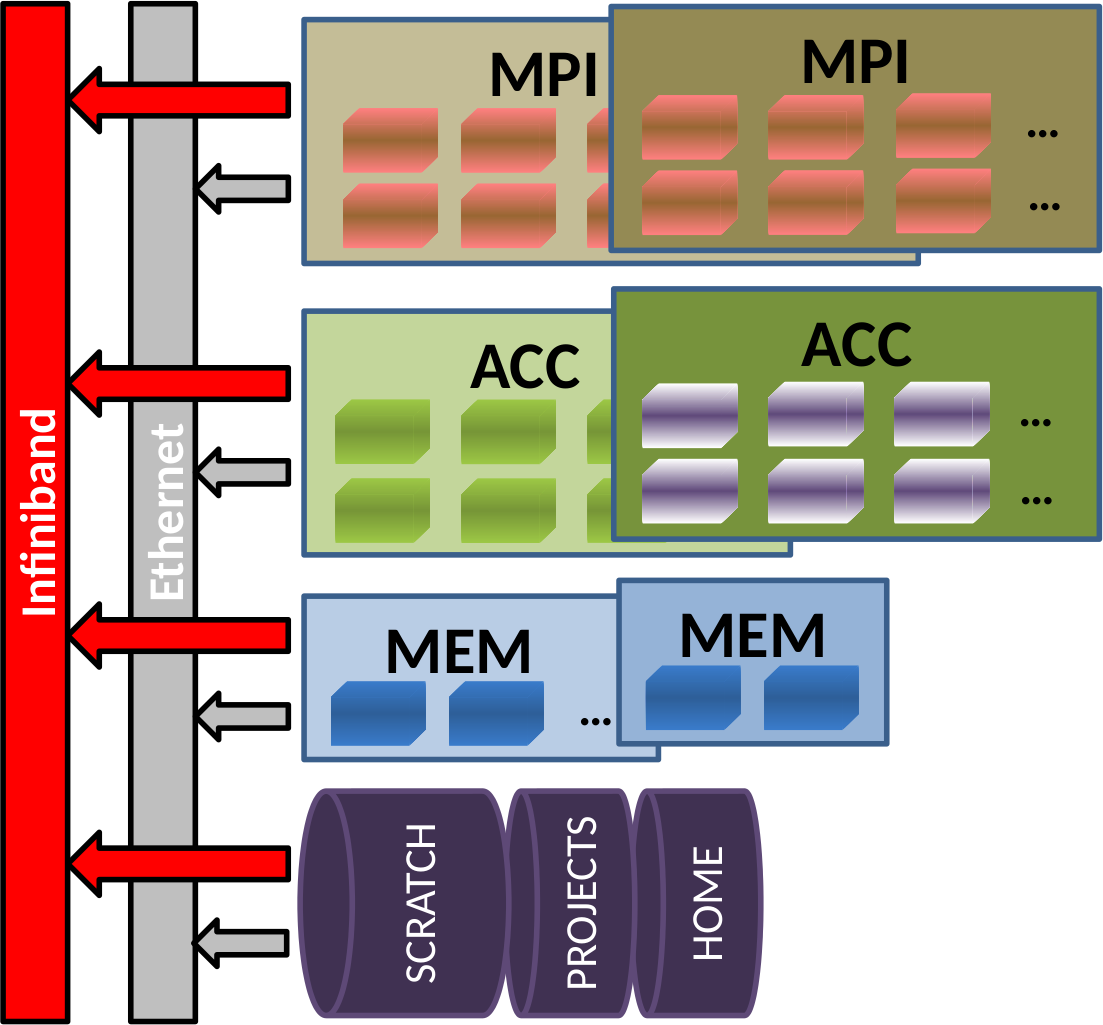
Das Cluster besteht grundsätzlich aus mehreren Sektionen:
MPI Sektion für MPI-intensive Anwendungen
ACC Sektion für Anwendungen, die von Akzeleratoren profitieren
MEM Sektion für Anwendungen, die sehr viel Hauptspeicher (pro Knoten) benötigen
Das Komplettsystem befindet sich im HLR-Gebäude (L5|08) auf dem Campus Lichtwiese und besteht aus mehreren gleichzeitig laufenden Ausbaustufen (ehem. Phasen).
Ausbaustufe 2 von Lichtenberg II wurde im Dezember 2023 in Betrieb genommen.
Ausbaustufe 1 von Lichtenberg II wurde im Dezember 2020 in Betrieb genommen.
- Jeder Rechenknoten einzeln mit entweder einem größeren oder mehreren kleinen Jobs/Programmen
- Mehrere Knoten gleichzeitig mit Inter-Prozess-Kommunikation (MPI) über InfiniBand
Die verschiedenen Ausbaustufen (ehem. Phasen) des Lichtenberg II sind für sich jeweils große Inseln in Bezug auf den Interconnect: nur die Rechenknoten derselben Phase können gleichzeitig und annähernd gleich schnell miteinander kommunizieren – ihr InfiniBand-Netzwerk ist (innerhalb ihrer Insel/Ausbaustufe) „non-blocking“ angelegt.
Im Gegensatz dazu ist die Bandbreite zwischen den Ausbaustufen/Inseln limitiert.
643 Rechenknoten und 8 Loginknoten
- Prozessoren: Zusammen ~4,5 PFlop/s Rechenleistung (DP-Genauigkeit, peak – theoretisch)
- Real erreichbar ca. 3,15 PFlop/s Rechenleistung mit Linpack
- Akzeleratoren: Zusammen 424 TFlop/s Rechenleistung (DP/FP64-Genauigkeit, peak – theoretisch) und ~6,8 Tensor PFlop/s (Half Precision/FP16)
- Speicherausbau: insgesamt ~250 TByte Hauptspeicher
- Alle Rechenknoten in einer großen Insel:
- MPI Sektion: 630 Knoten (je 96 Rechenkerne, 384 GByte Hauptspeicher)
- ACC Sektion: 8 Knoten (je 96 Rechenkerne, 384 GByte Hauptspeicher)
- 4 Knoten mit je 4x Nvidia V100 GPUs
- 4 Knoten mit je 4x Nvidia A100 GPUs
- MEM Sektion: 2 Knoten (je 96 Rechenkerne, 1536 GByte Hauptspeicher)
- NVIDIA DGX A100
- 3 Knoten (je 128 Rechenkernen, 1024 GByte Hauptspeicher)
- 8x NVIDIA A100 Tensor Core GPUs (320 GByte total)
- Lokales Storage: ca. 19 TByte (Flash, NVME)
- 3 Knoten (je 128 Rechenkernen, 1024 GByte Hauptspeicher)
Unter „Betrieb“/„Hardware“ finden SIe die Prozessor- und Beschleuniger-Details.
Das jüngste Speicher-System ist ein IBM/Lenovo „Elastic Storage System“ und ging am 20. Dezember 2022 in Betrieb. Das ESS besteht nicht mehr aus herkömmlichen (magnetischen) Festplatten, sondern ausschließlich aus NVMe-Flash-Speichern (insgesamt 576). Das sind Solid State Disks, bei denen kein SATA/SAS-„Controller“ mit eigenen Latenzen mehr im Datenpfad liegt – stattdessen sind sie direkt per PCI-Express an die CPUs der Storage-Server angebunden.
Das ESS stellt daher wesentlich höhere Bandbreite bzw. Durchsatz sowie wesentlich mehr I/O-Operationen pro Sekunde zur Verfügung als das alte System.
Insgesamt stehen momentan 6,1 PByte zur Verfügung: 2,1 PB Flash-Speichern (ab 2022) + 4 PB HDD (ab 2019).
Das parallele Hochgeschwindigkeits-Dateisystem ist „IBM Storage Scale“ (früher General Parallel File System), das für seine besonders hohe parallele Performance und Flexibilität bekannt ist.
Es stellt die gespeicherten Daten allen Cluster-Knoten über den schnellen Interconnect zur Verfügung, wobei alle Knoten gleichzeitig Lese- und Schreibzugriff haben.
Eine weitere Besonderheit an diesem System ist, dass alle Dateisysteme / Verzeichnisse über alle Platten bzw. SSDs/NVMe so verteilt werden, dass es kaum noch Geschwindigkeits-Unterschiede, trotz unterschiedlicher Konfiguration für den jeweiligen Zweck, mehr zwischen z.B. /work/scratch oder /home gibt. Außerdem bewirkt jede Kapazitätserweiterung somit auch eine substantielle Erhöhung des Speicherdurchsatzes.
Das vorige Speicher-System wird als sekundäre Ebene in ein sog. „Information Lifecycle Management“ überführt. Nur die jüngsten und am häufigsten gelesenen/geschriebenen Dateien verbleiben auf dem schnellen „All-Flash“-ESS. Eine auf Kapazität und Zeitstempel basierende Policy sorgt dafür, dass weniger „heisse“ Daten vom schnellen System auf das langsamere Ebene-2-System migriert werden. Weniger häufig benötigte Daten wandern also auf die langsameren magnetischen Festplatten des früheren Systems, um Platz und Leistung der neuen ESS für die aktuell laufenden Batch-Jobs freizuhalten.
Dieser Vorgang ist völlig transparent für Nutzer:innen und Jobs und findet nur intern – im selben Filesystem – statt. Eine solcherart auf das sekundäre System migrierte Datei erfordert keinerlei besondere Handhabung – aus Perspektive der Nutzer:innen und der Jobs ist die migrierte Datei genauso sicht- und zugreifbar, als gäbe es keine zwei hierarchischen Systeme.