
Overview
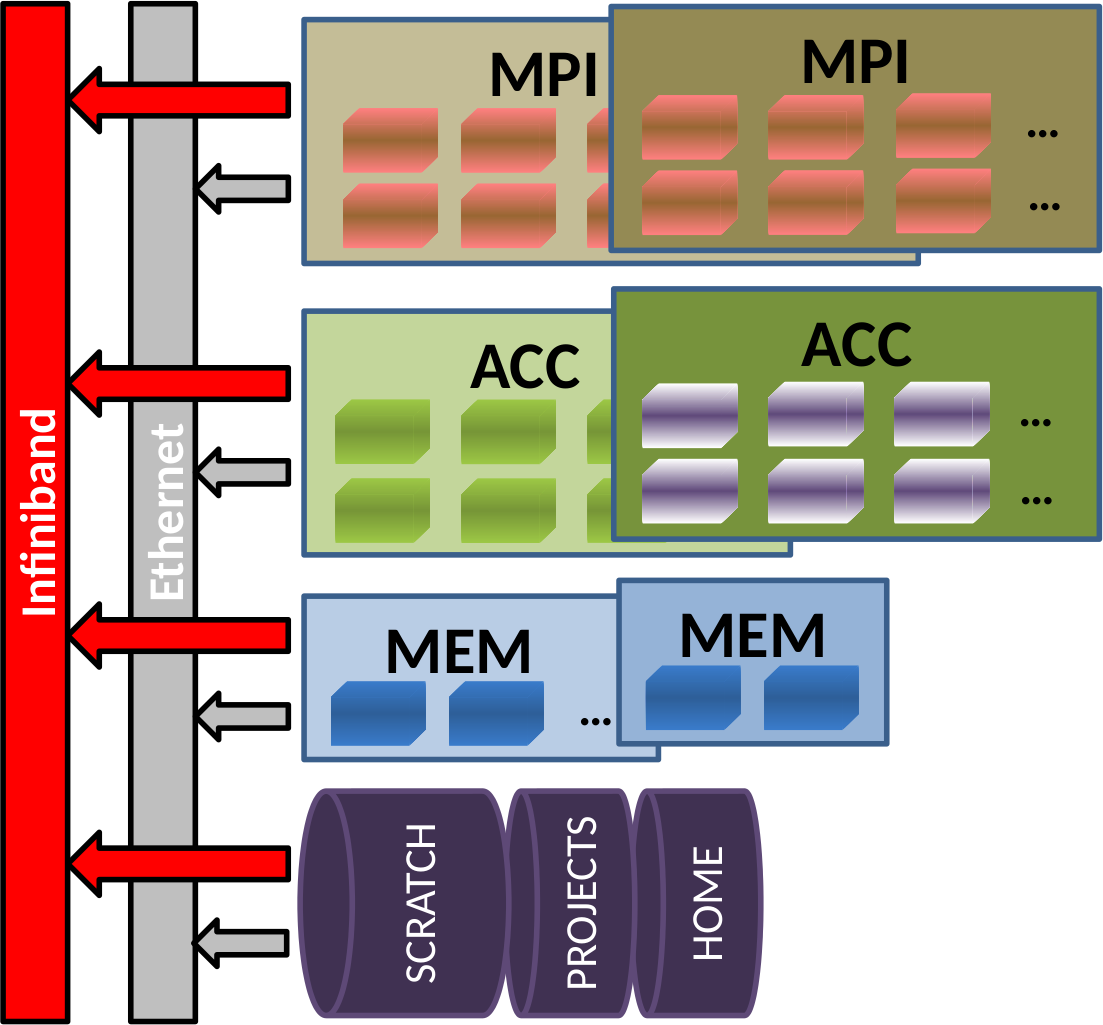
The cluster consists of several sections:
MPI section for MPI intense applications
MEM section for applications requiring lots of memory (in a single node)
ACC section for applications that use accelerators
The whole system is located at the HPC building (L5|08) on campus Lichtwiese, and consists of several stages, running concurrently.
Stage 2 of Lichtenberg II was operational in December 2023.
Stage 1of Lichtenberg II was operational in December 2020 (in testing since September 2020).
- Each node can be used as-is, ie. “single node”, with either one large or several smaller jobs/programs
- several nodes concurrently by interprocess communication (MPI) via InfiniBand
The distinct stages of the Lichtenberg II still are large islands with respect to their interconnect: only the compute nodes of the same phase (expansion stage) can reach and talk to each other with almost the same speed and latency – their InfiniBand fabric (inside one island/phase) is “non-blocking”.
In contrast, the bandwidth between distinct stages (islands) is limited.
643 Compute nodes and 8 Login nodes
- Processors: in total, ~4,5 PFlop/s computing power (Double Precision, peak – theoretical)
- Realistically achieved: ca. 3,03 PFlop/s computing power with Linpack benchmark
- Accelerators: overall 424 TFlop/s computing power (Double Precision/FP64, peak – theoretical)
and ~6,8 Tensor PFlop/s (Half Precision/FP16) - Memory: in total, ~250 TByte main memory
- All compute and accelerator nodes in one large island:
- MPI section: 630 nodes (each with 96 CPU cores and 384 GByte main memory)
- ACC section: 8 nodes (each with 96 CPU cores and 384 GByte main memory)
- 4 nodes with 4x Nvidia V100 GPUs each (total: 16)
- 4 nodes with 4x Nvidia A100 GPUs each (total: 16)
- MEM section: 2 nodes (each with 96 CPU cores and 1536 GByte main memory)
- NVIDIA DGX A100
- 3 nodes (each with 128 CPU cores, 1024 GByte main memory)
- 8x NVIDIA A100 Tensor Core GPUs (320 GByte total)
- Local storage: ca. 19 TByte (Flash, NVME)
- 3 nodes (each with 128 CPU cores, 1024 GByte main memory)
In “Operations”/“Hardware”, you can find prozessor and accelerator details.
The current storage system is a IBM/Lenovo “Elastic Storage System” and was put in operation 2022-12-20. The ESS consists entirely of NVMe flash drives (in total: 576), instead of legacy (magnetic) hard disks. NVMe are solid state disks directly connected via PCI express to the storage servers' CPUs, rather than by intermediary SAS or SATA controllers with added latency.
The ESS is thus capable of providing way more storage bandwidth and throughput as well as I/Os per second than the former system.
In total, 6,1 PByte of storage capacity is available: 2,1 PB flash drives (since 2022) + 4 PB HDD (since 2019).
The high speed parallel file system is “IBM Storage Scale” (formerly known as General Parallel File System), well known for its parallel performance and flexibility.
The stored data is being delivered to all cluster nodes via the fast interconnect, allowing all nodes concurrent read and write access.
One of the most notable features of the storage system is its constant distribution of all files and directories over all available disks and SSDs/NVMe. Unlike before, there is almost no performance difference any longer between eg. /work/scratch and /home. In addition, any expansion in storage capacity also eventuates a substantial gain in storage performance.
The former storage system will serve as a second tier in a so-called Information Lifecycle Management solution.
Only the most recent and the most frequently read/written files will remain on the primary NVMe drives, and a policy (driven by available space and access times) controls movement of less “hot” data to the second, slower tier. “Colder” data in less demand will thus wander over to the legacy magnetic hard disks, freeing capacity and performance on the fastest tier for the actual jobs' I/O.
This is entirely transparent to users and jobs and takes place only behind the scenes. A file internally migrated to tier 2 will not require to be treated or handled differently than others – from a user's and jobs' perspective, it will remain available and accessible without any change, as if there were no tier 1 and 2 at all.